Dell EMC’s VxRail is selling like hotcakes, I was lucky enough recently to attend a one day overview session on the product. The training was really good and I wanted to share what I had learnt to present a high level overview on what VxRail is about.
What is VxRail?
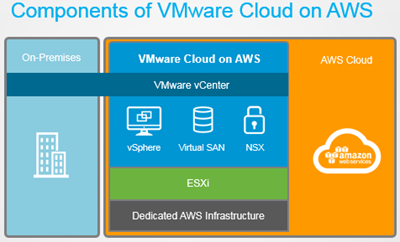
VxRail is Dell EMC’s hyper-converged offering. Hyper-converged appliances allow a datacenter in a box approach, rather than buying servers, storage and hypervisor separately hyper-converged appliances bundle the components into one package. The storage, compute and hypervisor components used by VXRail are as follows:
- Storage – VMware vSAN 6.6
- Compute – 14th Generation DellEMC PowerEdge servers
- Hypervisor – vSphere 6.5
Together the above form VXRail 4.5
What else do you get with VXRail?
You also get some other software bundled in:
- vCentre
- vRealize log insight
- RecoverPoint for VM’s
- vSphere Replication
- vSphere data protection
It is worth noting the ESXi licenses are not included
What is VxRack?
You may also hear VxRack mentioned, this is the bigger brother to VxRail with the software defined storage provided by ScaleIO. Networking using VMware NSX is also an option.
How many nodes do you need?
The minimum number of nodes required is three, although 4 is recommended to allow overhead for failures and maintenance. This is also the minimum number of nodes required to use erasure coding rather than mirroring for data protection.
How do you manage VxRail?
The system is managed from two places. You will be spending most of your time in the vSphere web console since all vSphere management is still performed from here. Also since the storage is being provided by vSAN this is also managed within vSphere. The second tool you will need to become familiar with is VxRail Manager.
vSphere Integration
There is the option to create a new vCentre which will be housed within the hyper-converged infrastructure it’s self or to use an external vCentre. The choice to use an internal or external vCentre can be set during the initial deployment wizard.
What is VxRail Manager?
The VxRail manager allows you to manage the hardware i.e. the servers in a VxRail deployment plus perform a number of other tasks including:
- Deployment – Initial deployment and addition of nodes
- Update – As this is a hyper-converged system upgrade of all components can be completed from the VxRail manager.
- Monitor – Check for events, and monitor resource usage and component status
- Maintain – Dial home support
The following shows a number of screenshots from within VxRail Manager
Physical node view

Logical node view showing resource useage
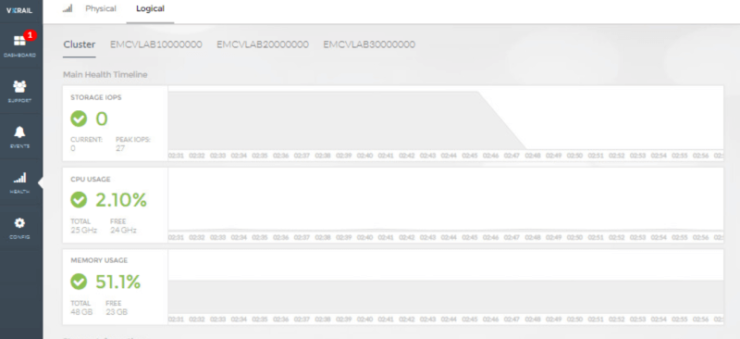
ESXi component status

What are the models?
You can see detailed specifications of all the models on the DellEMC site, this section just provides the major differences between the series
- S Series – Hybrid only
- G Series – Space saving format 2U can contain 4 appliances
- E Series – 1U hence supports less capacity than the other 2U nodes
- P Series – 2U supports twice the capacity of E series and is therefore suitable to more demanding workloads
- V Series – Same spec as P series plus GPU’s. Optimised for VDI environments
How do you add a node
You add a node using the VxRail Manager as shown in the screenshot below which is a non disruptive process. Hybrid and all flash models cannot be mixed plus the first three nodes in any cluster must be identical after this you can mix and match models . Although there is something to be said for maintaining consistency across the cluster so it is balanced and will probably make managing it easier in the future. The cluster can be scaled to a max of 64 nodes.

How do I take a node out for maintenance?
Since the data is stored inside each of the nodes there are some additional considerations when putting a node into maintenance versus using a traditional SAN. When you do put a host into maintenance mode the default option is ensure accessibility it makes sure all data is available during maintenance, although redundancy may be reduced.
vSAN summary
vSAN is VMware’s software defined storage solution, this means no specialist storage equipment is required and storage is provided by conglomerating the storage within each of the ESXi servers. Key concepts to understand
- Management – vSAN is managed from within vSphere and is enabled at the cluster level
- Disk groups – Each disk group consists of a caching disk which must be an SSD disk and 1-7 capacity drives. The capacity drives can be flash drives or spinning disks in a hybrid setup. All writes are made via the caching disk, 30% of its capacity is also reserved to act as a read cache.
- vSAN datastore – Disk groups are combined together to create a single usable pool of storage called a vSAN datastore
- Policy Driven – Different performance and availability characteristics can be applied at a per disk level on VMs
vSAN availability and data reduction
- Dedupe and compression – Enabled at the cluster level, not suitable for all workloads. If you have a requirement for workloads that do do not require dedupe/compression you would need multiple clusters
- Availability –
- Availability and performance levels are set by creating policies, you can have multiple policies on a single vSAN datastore
- Availability is defined in the policy setting fault tolerance method, the available choices are RAID-1 (Mirroring) and RAID-5/6 (Erasure Coding)
- RAID 1 is more suited to high performance workloads and will ensure there are two copies of the data across nodes
- RAID 5 – Stripes the data across nodes, more space efficient but reduced performance.