
Getting Trim
HPE are a bit late on this release, it’s normally January that people want to start losing weight. Well not 3PAR it’s gut busting, data crunching release comes in the form of the 3PAR OS 3.3.1 which combines existing data reduction technologies with new ones including compression. To see what else is new in the 3PAR OS 3.3.1 release check out this post.
The new data reduction stack in 3PAR OS 3.3.1 and the order they are applied is shown in the following graphic. Data Packing and compression are new technologies. There are no changes to Zero Detect but dedupe receives a code update. Zero detect is one of the original thin technologies that removes zeros from writes, most of you are probably already familiar with this so lets focus on the new and updated technologies, stepping through each in turn.

Dedupe
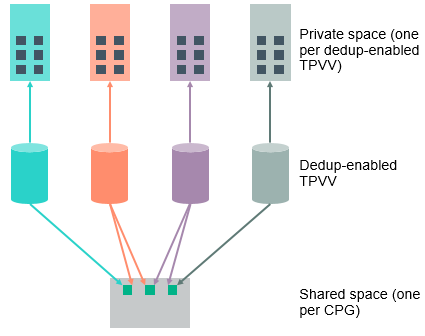
Dedupe continues to operate like before, analysing incoming writes in 16K pages assigning a hash for each and checking if this is unique to the system, this is all done inline before the data is written to disk. What does change is how deduped data is stored to disk, it is written to a shared area within the CPG versus to a private space in the volume previously. How data is now stored on disk is shown graphically below.

This amendment will effectively determine where unique and deduped data is stored. Given that the average dedupe level seen on a 3PAR is 2:1 it would be logical that half the blocks would be deduped and half unique, so why would we care where the blocks are stored given that the number of each is equal? Further analysis has shown that not half of data is deduped, but that 10% of data is deduped several times over giving an overall dedupe ratio of 2:1. In summary a significantly greater proportion of data will be unique versus deduped.
There are two elements to how deduped data is stored in a system, a private space that exists inside every volume and a shared space that exists one per CPG. When a write comes into the system and has a unique hash (i.e. it has never been seen before) it is placed in the private area of the volume. When a write comes into the system and has a known hash (i.e. it is a duplicate) it is placed in the shared space. We know that approximately only 10% of data will be deduped, and therefore the net results of this design is that the majority of data will sit in the private area. This is advantageous as when a block is deleted that exists in the shared area several checks need to be made to check if this block is still required. The process to perform these sanity checks before deleting the block is too resource intensive to perform real time, so must be performed post process. Post processing is disadvantageous as it adds overhead to the system. As in the new design less data sits in the shared area there is less need for this post processing which makes dedupe more scalable.
The new version of dedupe is intended to allow dedupe and compression to function together in the same VV (Virtual Volume). Up until now dedupe was enabled with the use of the TDVV (Thin Deduplicated Virtual Volume), this is now no longer required as dedupe is just an attribute of a volume that can be enabled. Once enabled dedupe is performed across all VV’s in a CPG with the dedupe attribute turned on and will be at a 16K page level. Consider this when planning your system layout to ensure that like volumes are grouped in the same CPG to maximise dedupe.
The good news is there is no additional licence cost for using dedupe. This new version of dedupe is still driven by the ASIC and will be available to all models with the GEN 4/5 ASIC so this is the 7000, 8000, 10,000 and 20,000 series. Like the existing version of dedupe the Virtual Volumes must be on flash drives, so this also negates the use of AO with dedupe.
If you are already using the existing form of dedupe you will need to create a new CPG and then do a Dynamic Optimization operation to migrate volumes to the new CPG. The necessary changes to enable the updated version of dedupe will be made automatically when the volume migrates.
Compression
Again let’s start with the good news, compression will be available at no additional licencing cost, however it is only available on the GEN 5 systems i.e. the 8000 and 20,000 series. As with dedupe this option is only available on data stored on flash, so again cannot be coupled with AO. Compression takes place at a per VV level and aims to remove redundancy. HPE are estimating an average saving with compression of 2:1. Dedupe and compression can be combined together and HPE are expecting an average of 4:1 data reduction when used together.
At release when using compression there will be no support for Asynchronous Remote Streaming. Remote Copy is supported but data in transmission will not be deduped or compressed. The data will be deduped and compressed again at ingestion to the target if these options are enabled.
Data Packing
3PAR writes to SSD’s in 16K pages, however after compression the 16K pages will end up with a sub 16K size, not optimised for writing to SSD. The inefficiency comes with pages being written across block boundaries, to tackle this HPE have developed the Data Packing technology. Data packing takes a number of these odd sized pages and combines them into a 16K page, reducing the need for a post process garbage collection on the SSD’s. The odd sized pages grouped together will usually all come from the same volume, since this improves the chances these blocks will all need to be changed at the same time in the future. The technology sounds very similar to when I pack a suitcase and stuff is sticking out everywhere, then my wife comes along and makes it all fit in nicely. She has denied any part in the development of this new technology.

Getting running with dedupe and compression
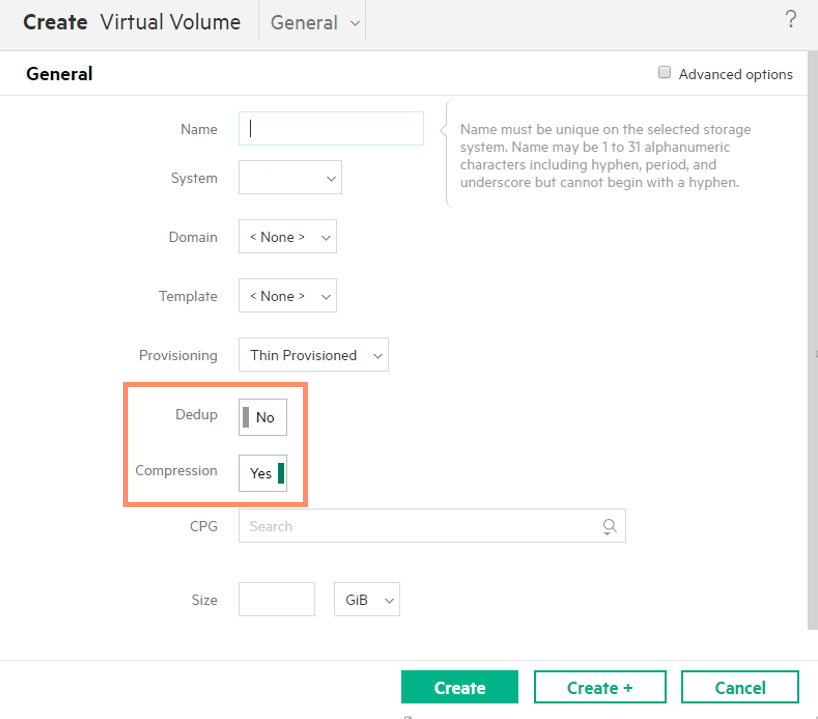
First of all you need to get yourself upgraded to 3PAR OS 3.3.1 and remember you need a minimum of a GEN 4 ASIC for dedupe and GEN 5 for compression. Once running 3PAR OS 3.3.1 dedupe and compression can then be enabled via the SSMC on a per volume basis. Given this per volume granularity, the attributes can be set appropriately for the data contained in each, for example a video format that was already deduped and compressed would just be thin provisioned but VDI volumes could be deduped and compressed. The option to set dedupe and compression in SSMC is shown in the screenshot below, they can be set together or independently.
Remember if you are using dedupe already and want to take advantage of the enhanced performance of the latest version of dedupe you will need to do a Dynamic Optimization operation to move existing volumes to a newly created CPG.
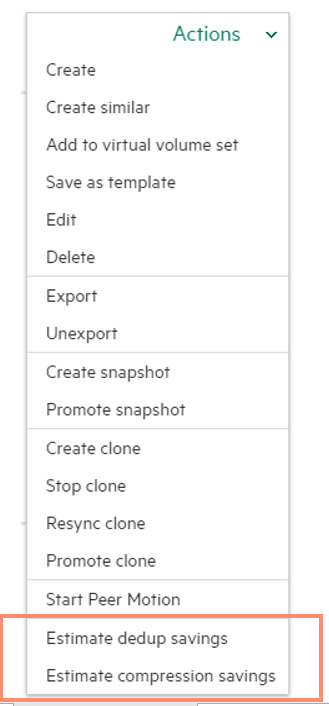
You can also use the SSMC to estimate the savings you will get from dedupe and compression.
Data that is already encrypted or compressed at the application level will not be suitable for compression. However if encryption is required the recommendation would be to use drive level encryption so that compression can still take place.
To make sure that you don’t miss any more news or tips, you can get e-mail updates, or follow via Face Book, LinkedIN and Twitter.
Further reading
Adaptive data reduction brochure
What is HPE 3PAR Adaptive Data Reduction
As I have seen in a 3PAR presentation with latest news is, that in case dedupe and compresseion is used in combination, deduplication is not done anymore through the ASIC, instead it is also done with CPU ressources. Therefore performance could decrease quite a lot. Is this correct?
Hi thanks for the question. The ASIC is always used for dedupe and CPU for compression
Do you know how compression works together with dedupe? As far as I understand it, compression creates with Data packing “new” 16k pages. I assume that it might be hard for dedupe to work with these new pages. Do you know what I mean?
Hi, dedupe and compression definitely work together, whilst some workloads may benefit from one data reduction technique more than another. It would be hard to think of a modern storage system that doesn’t have the two work together. Also remember that it dedupes first and then compresses, 16K is the standard page size for 3PAR to write to SSD.
Thanks for your reply.
I understand, that dedupe is before compression. But if I have a 16k Block A. There is no other 16k Block like this Block A. Now I compress my Block A and put it together with other compressed Blocks to create a new 16k Block B.
A few days later a new 16k Block C is written to the 3PAR. Block C is exactly like Block A. How is the 3PAR now able to compare Block A and B for dedupe? It mitght be able to compare Block B and C, but they are not looking the same.
Do you know what I mean or what I’m trying to understand?
As far as I’m aware Compression only works on the remaining non-Deduplicated pages when configured together, as there is little to be gained by compressing an already Deduplicated page (with many pointers to that page).
Nikolai,
it can tell that they are the same because before even writing to disk, it has calculated the hash for the block. If the hash matches one that is already in the hash table, it knows it does not need to write a second copy to disk.
–Brian
Hi d8taDude, appreciate your efforts.
We have a 3par 7200 with tpvv on an all FC tier with compression enabled. For space and performance we are adding an SSD tier. We are not going to use AO/DO, instead we will pin vvols to the SSD tier and move high intensive data sets there.
Question: With the 7200c being that it uses the G4 Asic, with SSD based vvols, can compression + dedupe for a vvol be enabled or must you use either or, the former being compression and the latter being dedupe?
Thanks
Hi
Compression can only be used on the SSD tier and the 8000, 9000 and 20000 systems. So the available choice for yourself will be deduplication.
If you are already using the existing form of dedupe you will need to create a new CPG and then do a Dynamic Optimization operation to migrate volumes to the new CPG. The necessary changes to enable the updated version of dedupe will be made automatically when the volume migrates.
When you say dynamic optimization, we were told that this is a very disruptive process. as in snapshots deleted. RC stopped etc. Does it still hold?
also do you have an idea how long this process takes for example for an 8 TB volume from VV2 to VV3.
And I have yet another question if I want to disable deduplication on VV2 how disruptive would that be?
how much performance impact when turn on the dedup and compression?
thanks
The simple answer is it depends :). As a rough guide expect a greater performance impact when using compression, dedupe less so. The 3PAR best practice guide has a list of workloads that are and are not suitable for dedupe. Best thing is to do some before and after tests with your workloads. Also make sure you are running fimrware version 3.3.1 which included enhancements to dedupe. Good luck and feel free to report back with the results of your tests