
3PAR storage Remote Copy Failover, Recovery & Restore using IMC
Today we have a highly detailed guest post covering the 3PAR remote copy failover and recovery process. If you fancy writing a guest post check out this post.
About the author
Written by Deepak Garg, a technocrat with over 10+ years of experience in storage administration and with technical expertise in managing the technical support functions. Expert on HPE 3PAR, HPE StoreOnce, HP EVA Storage, HP MSA/P2000, LHN and many other HPE products
Introduction
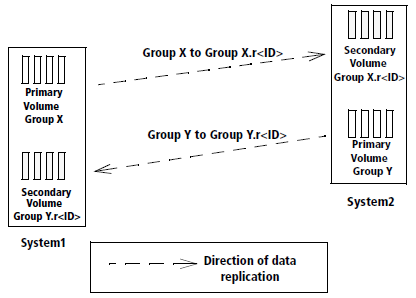
Unidirectional 1-to-1 Configuration
A unidirectional 1-to-1 remote-copy configuration is composed of one remote-copy pair. Each storage system in the pair plays only one role: one system is the primary system, and one system is the backup system.
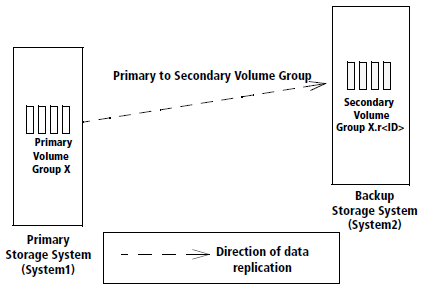
Bidirectional 1-to-1 Configuration
A bidirectional 1-to-1 remote-copy configuration is composed of one remote-copy pair.Each storage system in the pair functions as both the primary and backup system and each system contains both primary and secondary volume groups.
Each system provides backup for the other, according to the direction of replication specified for each volume group. Below figure illustrates a bidirectional 1-to-1 remote-copy configuration.
System Information during Failover for 1-to-1 Configurations
Asynchronous Periodic Mode for 1-to-1 Configurations
When a failure occurs on systems with asynchronous periodic mode volume groups such that all links between the systems are broken, the following actions occur:
- After 60 seconds, the system marks the sending links as down.
- After another 200 seconds, the system marks the targets as failed
Recovering from Disaster for 1-to-1 Configurations
For the remote copy failover, recover and restore operation there are defined steps involved which need to followed as below.
- Failover
- Recovery
- Restore
Failover
a) Stop Remote Copy Group
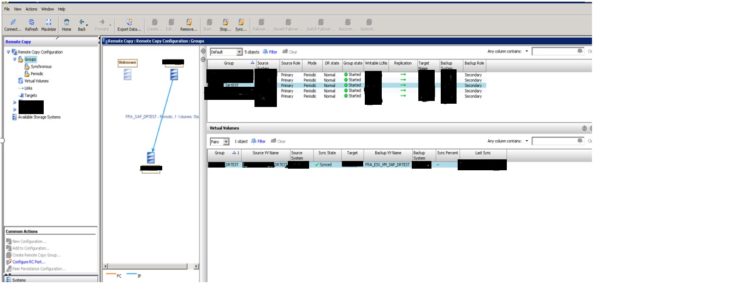
Reverse the role of all volume groups on the system that is still in normal operation (the failover system). Here we will consider that system “System-A” is in failed state or having some planned maintenance activity. Below screen shot shows where we want to do the failover of replication group “DRTEST” from primary system System-A to System-B
During this first of all we have to stop the remote copy replication group “DRTEST” to do the testing.
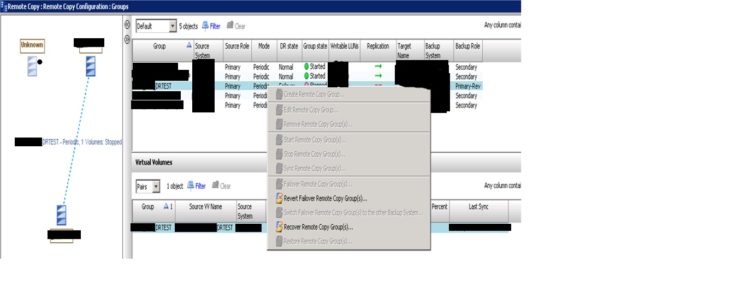
From the 3PAR management console, click on remote copy from the left pane. After this click on the groups and verify the replication group listed on the right side as shown below in picture.
We will be doing the failover of “DRTEST” replication group. So right click on “DRTEST” and click Stop Remote Copy Group(s) as shown below in picture:
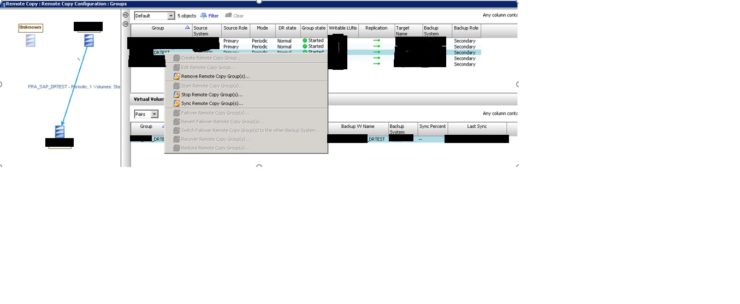
Once clicked on Stop Remote Copy Group(s) option a pop-up window as shown below will open which will state that remote copy mirroring will be stopped. Click on OK to proceed.
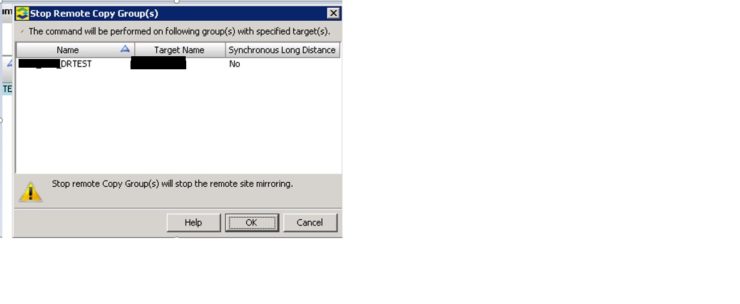
Once we stop Remote Copy Group, replication from source to target will be stopped.
b) Failover Remote Copy Group
Once the remote copy group is in failed state then we will see that Group state is a stopped state. Now we have to right click on the failed remote copy group (in our case we are preparing example with remote copy group “DRTEST”) and click “Failover Remote Copy Group (s)..” option as shown below
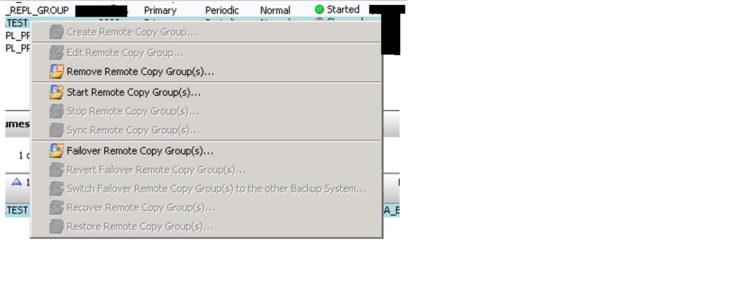 Now one pop-up window will open click OK and after that one more pop-up will open and click yes here
Now one pop-up window will open click OK and after that one more pop-up will open and click yes here
Note:- After this failover will be executed for the selected group. The failover operation changes the role of secondary groups on the backup system (i.e. System-B) from “Secondary” to “Primary-Rev”. Any LUNs (VLUNs) associated with the volumes in the selected groups become writable by hosts connected to the backup system (backup system is System-B in our case). These VLUNs will be in writable permission from both side 3PAR so we must ensure that no write operation on VLUN from primary site.
As per picture below, click YES to continue and the failover operation will start.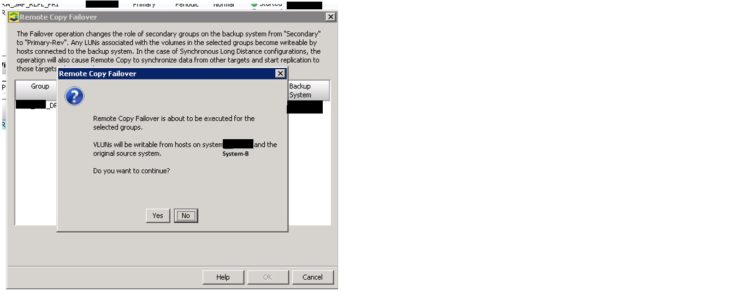 Now there should be Group state as “stopped” as per below picture. Replication status in the table will be as “Stopped” and Backup system (i.e. System-B) will show its role as “Primary-Rev” with DR state as “Failover”.
Now there should be Group state as “stopped” as per below picture. Replication status in the table will be as “Stopped” and Backup system (i.e. System-B) will show its role as “Primary-Rev” with DR state as “Failover”.
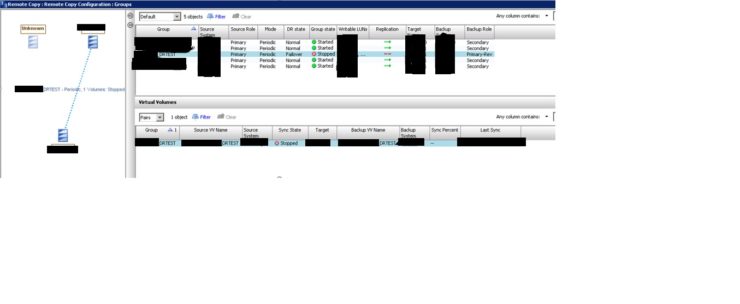 This completes all failover steps.
This completes all failover steps.
Recovery
a) Description of Recovery Option
Recover option will recover the failed system (in our case failed system is System-A). When both systems in the remote-copy pair are ready to resume normal operation, reverse the natural direction of data flow and resynchronize the systems.
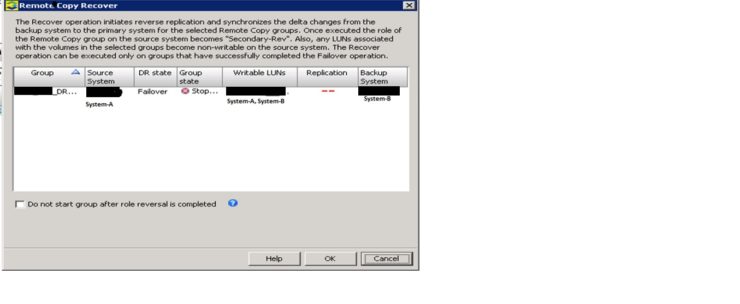
At this time we have to right click on the replication group which was failed earlier (in our case it is “DRTEST”) and click on “Recover Remote Copy Group (s).. This will copy data / initiates reverse replication and synchronize the delta changes from the reversed volume groups on the failover system (System-B) to the corresponding volume groups on the recovered system (System-A).
Once executed the role of the remote copy group on the source system (System-A) becomes “Secondary-Rev”. Also, any LUN associated with the volumes in the selected groups become non-writable on the source system (System-A).
Note: – The recovery operation can be executed only on groups that have successfully completed the failover option.
b) Recover Remote Copy Group
Below two pictures shows the process on how to put a replication group in recover state and then click YES in pop-up window. Right click on the replication group which was failover and click on the option “Recover Remote Copy Group(s)”
 Once clicked on OK prompt, there will be one more pop-up, press yes now. Important to note that VLUNs will not be writable now on source system “System-A” and it will be in writable mode on backup system “System-B”.
Once clicked on OK prompt, there will be one more pop-up, press yes now. Important to note that VLUNs will not be writable now on source system “System-A” and it will be in writable mode on backup system “System-B”.
Now, we should be able to see Source role for “DRTEST” on source system should be “Secondary-Rev” and “Primary-Rev” on the Backup system role as shown in below picture. Now the DR state will be in “Recover” stat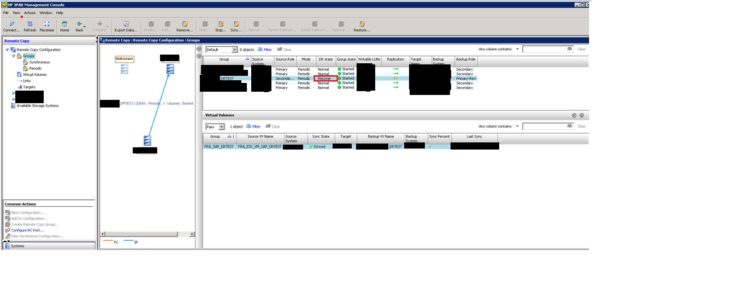 c) Verification:
c) Verification:
1 Issue the showrcopy command from the CLI on the failover system (System-B).Verify the following:
- The Status of the target system (recovered system – “System-A”) is ready
- The SyncStatus of all volumes in the Primary-Rev volume groups is Syncing.
- The Status of all sending links is Up,
2 Issue the showrcopy command from the CLI on the recovered system (System-A) Verify the following:
- The Status of the target system (System-B) is ready
- The Status of all sending links is Up
- The Role of the synchronizing volume groups is Secondary-Rev
- The SyncStatus of all volumes in the Secondary-Rev volume groups is Syncing
Restore
a) Description
Once the recovery is completed for the remote copy group then we must restore back the actual state of replication group. I.e. bring the replication group (in our case it is “DRTEST”) back to “System-A” as primary role and again replication from the primary system (System-A) to backup system (System-B).
b) Procedure to Implement
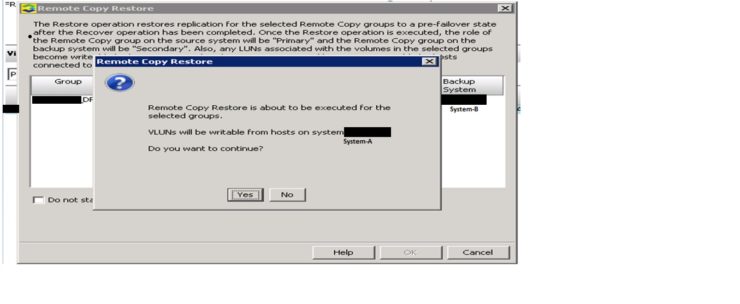
For doing this right click on the replication group and click “Restore Remote Copy Group(s)..”.This restore operation restores replication for the selected Remote Copy group to a pre-failover state after the recovery operation has been completed. Once the Restore operation is executed the role of the remote copy group on source system (System-A) will be “primary” and the Remote copy group on the backup system will be “Secondary”. Also, any LUNs associated with the volumes in the selected groups become writable by hosts connected to the source system (i.e. System-A) and become non-writable by hosts connected to the backup system (i.e. System-B)
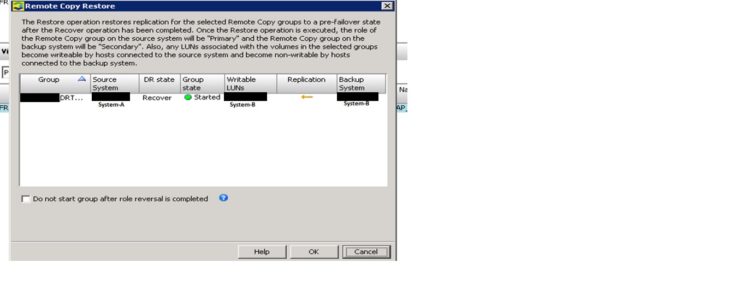 And once we will click on the OK in the above pasted picture, then there will be one more pop-up to click Yes or No, we have to click “Yes” to complete the process.
And once we will click on the OK in the above pasted picture, then there will be one more pop-up to click Yes or No, we have to click “Yes” to complete the process.
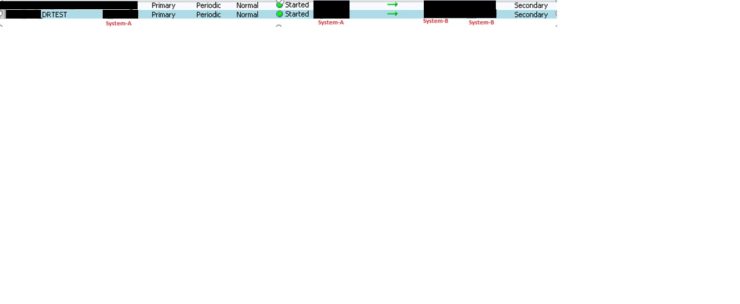
 Now the system should be able to see the status of restored replication group as it was in actual state. Below picture shows the actual status with System-A system as Primary and normal state and replication pointing from System-A to System-B.
Now the system should be able to see the status of restored replication group as it was in actual state. Below picture shows the actual status with System-A system as Primary and normal state and replication pointing from System-A to System-B.
.
Nice write up.
Be notice a failover is normal only used when your primary site is down. So when use a “planned” failover, host(s) MUST be down during this.
As soon you stop the RC group. And a failover command is given, both array’s present the LUN, and cause data inconsistent at both sides in less then a second.
Before the “PLANNED” failover, you need to unpresent the vlun at primary site first. (So host(s) must be down.)
Same apply for restore command, this is with hosts down.
Off course you can use other method to return to the original site without take the hosts offline.
If the primary site went down, and you initiated a failover. Then when the primary will be come back, it go in failsafe mode by itself as it notice the failover. (And this failsafe prevent, presenting the vluns at primary)
I hope this sound as expected for you.
Hi
Thanks for the feedback. Yes good tip on the need to shutdown when testing.
Richard
Please note that the IMC (Inform Management Console) has been superseded by SSMC (StoreServ Management Console.
IMC is a fat client application. Some more recent 3PAR features like File Persona, 3DC Peer Persistence etc. cannot be configured and controlled from IMC. The last supported 3PAR OS version is 3.2.2.
SSMC has a user friendly HTML interface and can support all 3PAR systems running 3PAR OS 3.1.3 or higher.
Since most 3PAR systems are nowadays managed with SSMC it would be great to see your post with SSMC used.
Keep it up
StorePete
Hi StorePete
new article with SSMC is also published now as per feedback.
where is it?
The status of the luns during replication shows Read/Write in both source and DR. Even after failover it says Read/Write. is this valid? or just an incorrect state?
I was reading the RC 3.3.1 document and found following contents not according with your description “Asynchronous Periodic Mode for 1-to-1 Configurations”.
When a failure occurs on systems with asynchronous periodic mode volume groups such that all links
between the systems are broken, the following actions occur:
• After 5 seconds, the system detects the target failed.
• After another 200 seconds, the system declares the RC links are down and stops the RC group
Thanks for the updated info
Here is one for you. How do I force delete a Remote Copy Group if the node can not communicate with the other node? We keep getting an error it can not delete the group because it cannot communicate with the other node (isolated LAB system)
This is an unusual situation as normally you would want both arrays to know about the change. Could you not establish a connection whilst you made the deletion?