The process for downloading and installing the 3PAR Management Console is covered in this post. The 3PAR Management Console was the traditional tool for managing your 3PAR systems. 4.7.3 was the last incarnation of IMC, since it has been superseded by the StoreServ Management Console (SSMC) which gives you a pretty web based management interface. If you want to get started with the SSMC you can get ready with our SSMC install guide and beginners SSMC posts.
If you are running 3PAR OS 3.3.1 and below or just prefer the traditional management console then read on.
Downloading the 3PAR Management Console
1 You can download the 3PAR Management console, form this direct link which takes you to the 3PAR software depot. If you just browse the depot its hidden.
Installing the IMC
Its dead easy but here I will walk you though the process with screen shots.
1 Choose to run setup.exe for the v4.7 files you just downloaded. In my case from inside the Windows directory of the ISO
2 Just choose next at the 3PAR management console introduction screen
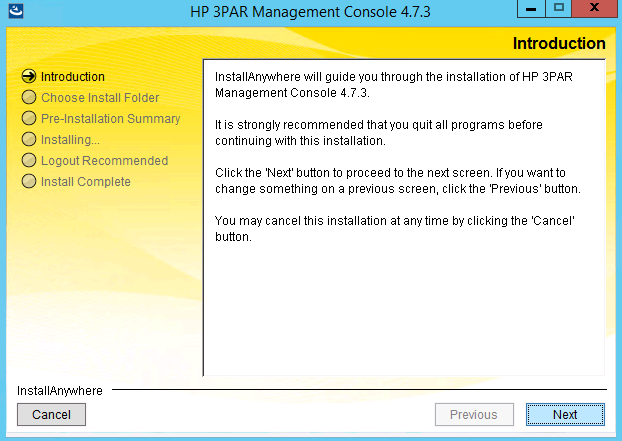
2 Choose the install location, leave it default unless you have specific reason to move it and then click next
3 A summary of the install appears, check your selections and then click install
4 A couple of information screens appear during the install, no need for any input. Just wait for the install to complete.
5 That’s it just click done, and you have the latest version of IMC installed!

Don’t forget to install your other 3PAR management tools the CLI and SSMC
You can learn more about the IMC in the HPE 3PAR Management Console User Guide